Design Long Term Memory in Drawhisper

LLM Limitations in Long Context Windows
Recent large language models (LLMs) have made remarkable progress in solving intricate problems, completing complex tasks, and sustaining multi-round conversations. Reasoning-centric models such as DeepSeek-R1, GPT-5, and Claude 4.5 Opus routinely reach—or even surpass—domain experts, giving teams unprecedented leverage.
At the same time, these models now ship with context windows measured in millions of tokens, allowing them to reference long-running conversations and early-stage knowledge. Yet even the strongest models still struggle to find the proverbial needle when the haystack is littered with noise. This loss of precision over long transcripts is known as context rot. The challenge compounds when a user starts a fresh session and discovers the model has forgotten everything learned previously.
Training new capabilities directly into the model also remains cost-prohibitive. Once fine-tuning finishes, the learned knowledge is locked into the weights, meaning the model cannot absorb newly surfaced facts in real time during a chat.
RAG and Memory Management
To tackle aforementioned drawbacks, researchers designed several systems to augment model's ability. The most commonly used technology of augmenting un-trained knowledge for model is RAG - retrieval augmented generation. With agentic design, the model could use their agentic tools (e.g., retrieval functions) to retrieve most relevant knowledge from a Vector Database based on user question, where stores new knowledge which the model has never seen before. Typically, a retrieval method transforms user question into a high dimensional vector utilizing an embedding model, then a similarity algorithm (e.g., Cosine or Euclidean distance) is used to get the most relevant vectors from the vector database. Later, a re-ranker model can be used to re-rank the best records from multiple candidates. Finally, semantic content stored in the retrieved records can be used as model context to answer the user's question.
Context loss across chat histories can be addressed with similar techniques, but the engineering design becomes more sophisticated. Recent updates in ChatGPT introduced an explicit memory feature: you can tell ChatGPT what to remember, it can proactively capture notable details, and it will surface those memories in future sessions. Under the hood, the feature is powered by RAG-style retrieval with significant product engineering on top.
Context Engineering in Drawhisper
With that foundation, we designed a long-term memory system tailored for Drawhisper role-play chat experience. It automatically creates readable memories as users talk to their favorite characters, helping them form deeper bonds over time.
In general, the agent generates one to three memories when the chat history exceeds 2,048 tokens (roughly 20 chat rounds, or 40 individual messages). First, it summarizes the recent dialogue with a reasoning model (deepseek-reasoner in our deployment). That summary flows to an extractor model, which splits the content into structured chunks. Each chunk is expressed in JSON and includes a title, body content, and type. We currently support seven memory types, including conversation, important event, preference, fact, emotion, worldbuilding, and relationship, the extractor assigns the best fit during generation.
Next, the agent embeds each chunk and stores the resulting vectors, along with metadata such as the source transcript and character information, in a vector storage. After the embeddings are safely written, the agent persists the memory and vector index in our database so the chat client can display, edit, or reuse it.
// an example memory chunk
let memory_chunk = {
title: 'memory title',
content: 'memory content ...',
type: 'MEMORY_TYPE'
}
To summarize, the Memory Agent runs through five stages:
- Generate a detailed summary of the recent chat history
- Extract memory chunks and assign the best-fit type
- Embed the source content for each chunk
- Persist embeddings to the vector store and record the memory in our database
- Notify the chat client about new memories
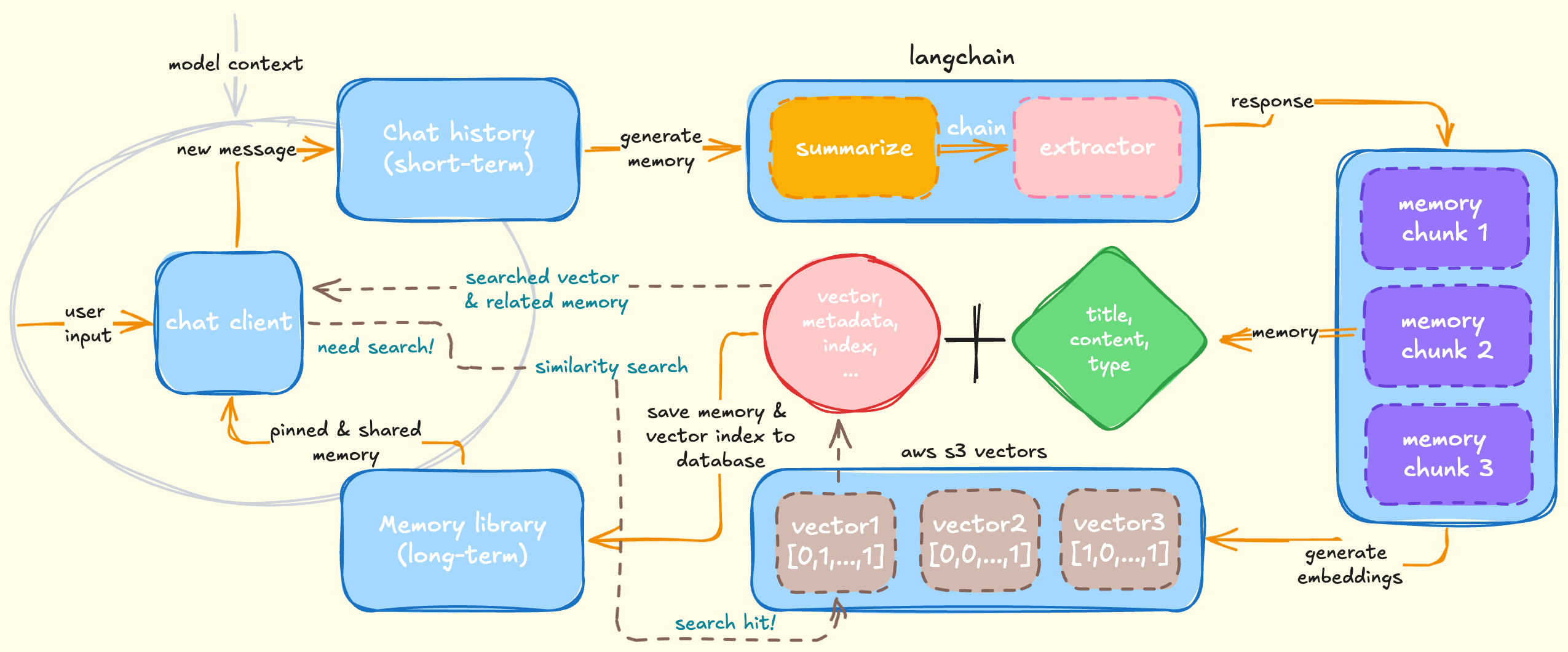
We orchestrate the first two stages with LangChain.js agent chain, turning raw dialogue into structured, user-friendly memory snippets. For vector storage and retrieval we rely on AWS S3 Vectors, which gives us durable storage and low-latency similarity search. Everything runs asynchronously in the background, so the user experience stays smooth.
Inside the chat client, users can pin memories to the current thread or share them across multiple chats derived from the same character. To expand each character's verisimilitude and versatility, we also support user-created scenes. Scenes inherit the core character configuration but add detailed stage directions and scenario information, enriching the context provided to the model.
During a conversation the model receives short-term context (recent messages) plus long-term context (pinned or shared memories). When a user references a preference or an old story absent from the live context, the system embeds the new query, retrieves relevant memories via similarity search, and injects the source content into the model prompt.
This memory system offsets context rot by delivering a curated memory stream that keeps responses grounded and authentic. We plan to publish a deeper technical report on the memory system's impact once we have sufficient chat data, stay tuned by registering at Drawhisper!